AI
Cloud
AWS
Serverless
Open Source
DocProof
AI-Powered Document Validation Engine for Onboarding Workflows that automates document collection, extraction, and validation.
Project Highlights
1
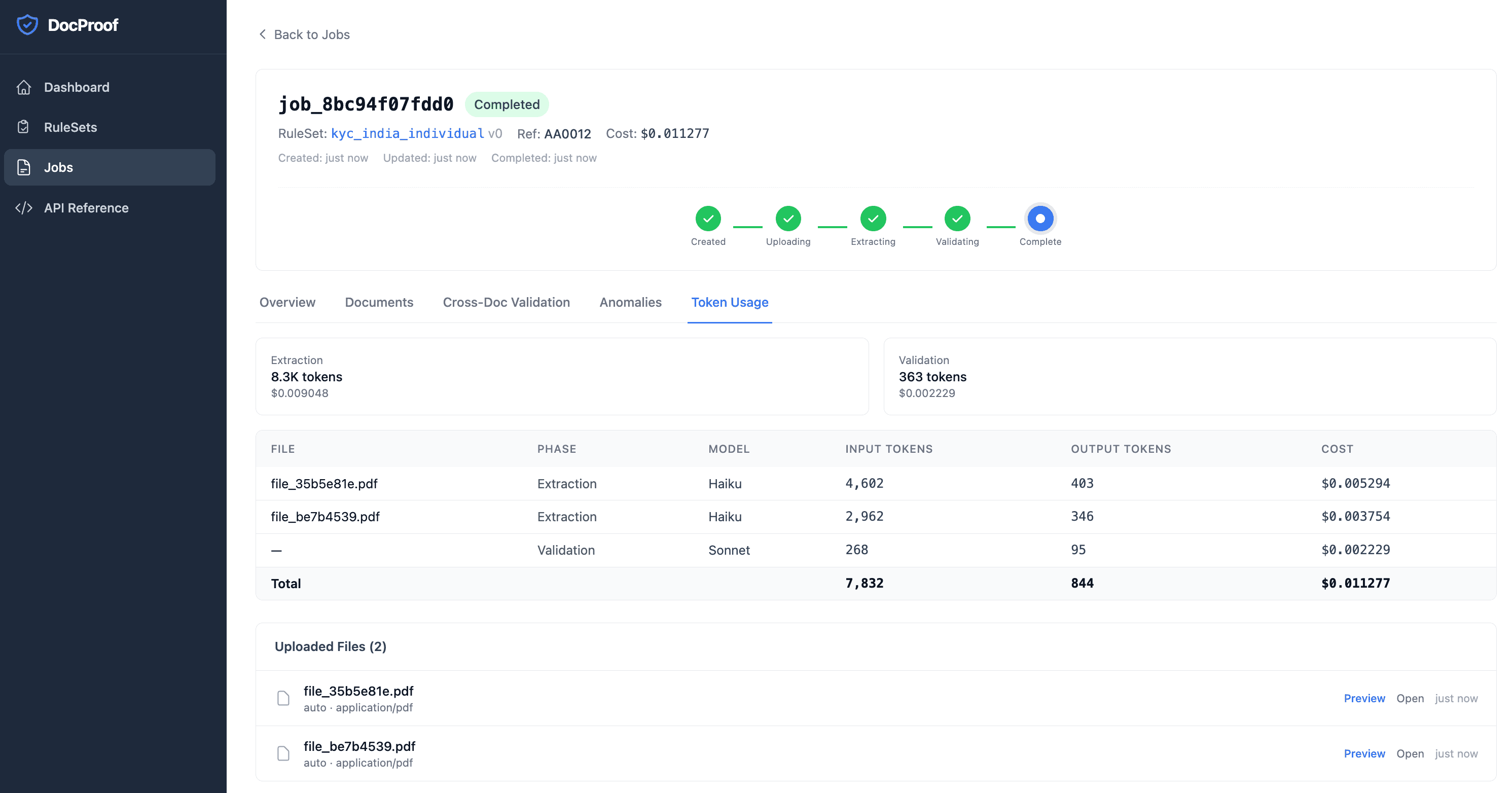
Claude-Powered Extraction
LLM-native document understanding using Haiku 4.5 via Bedrock.
2
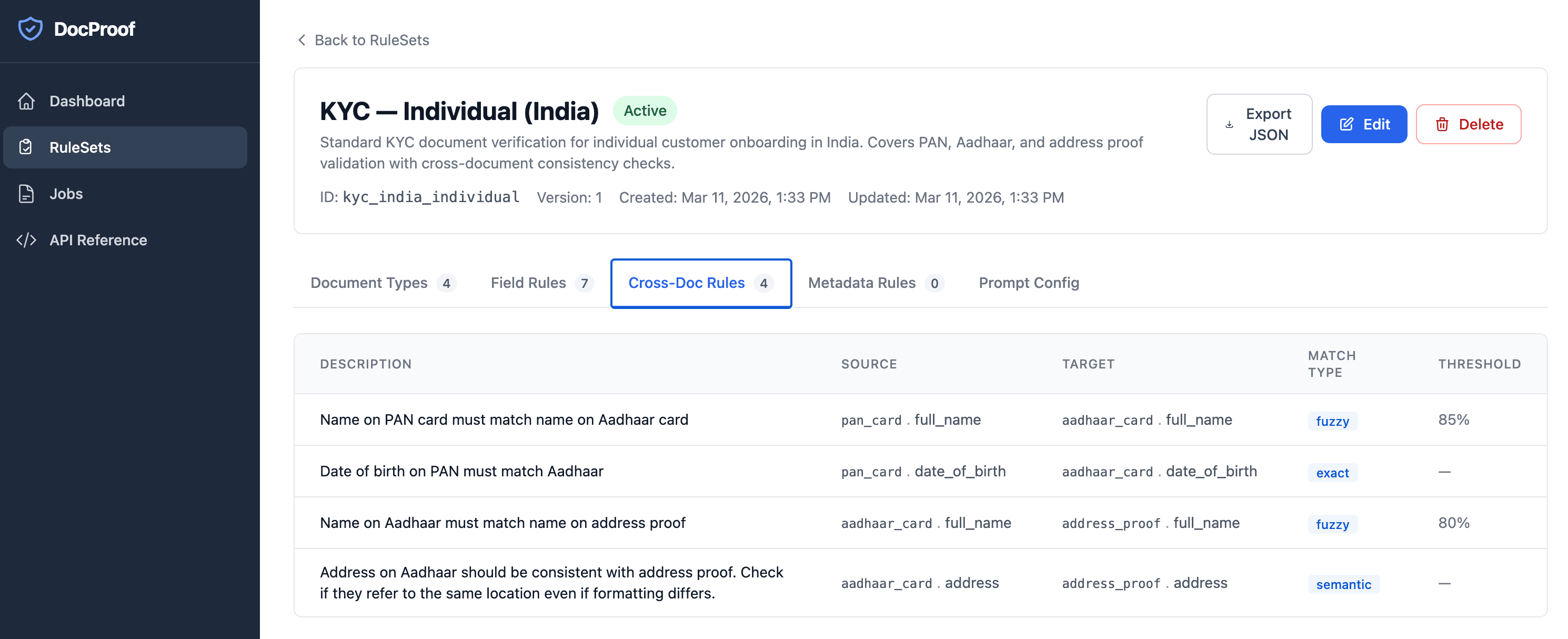
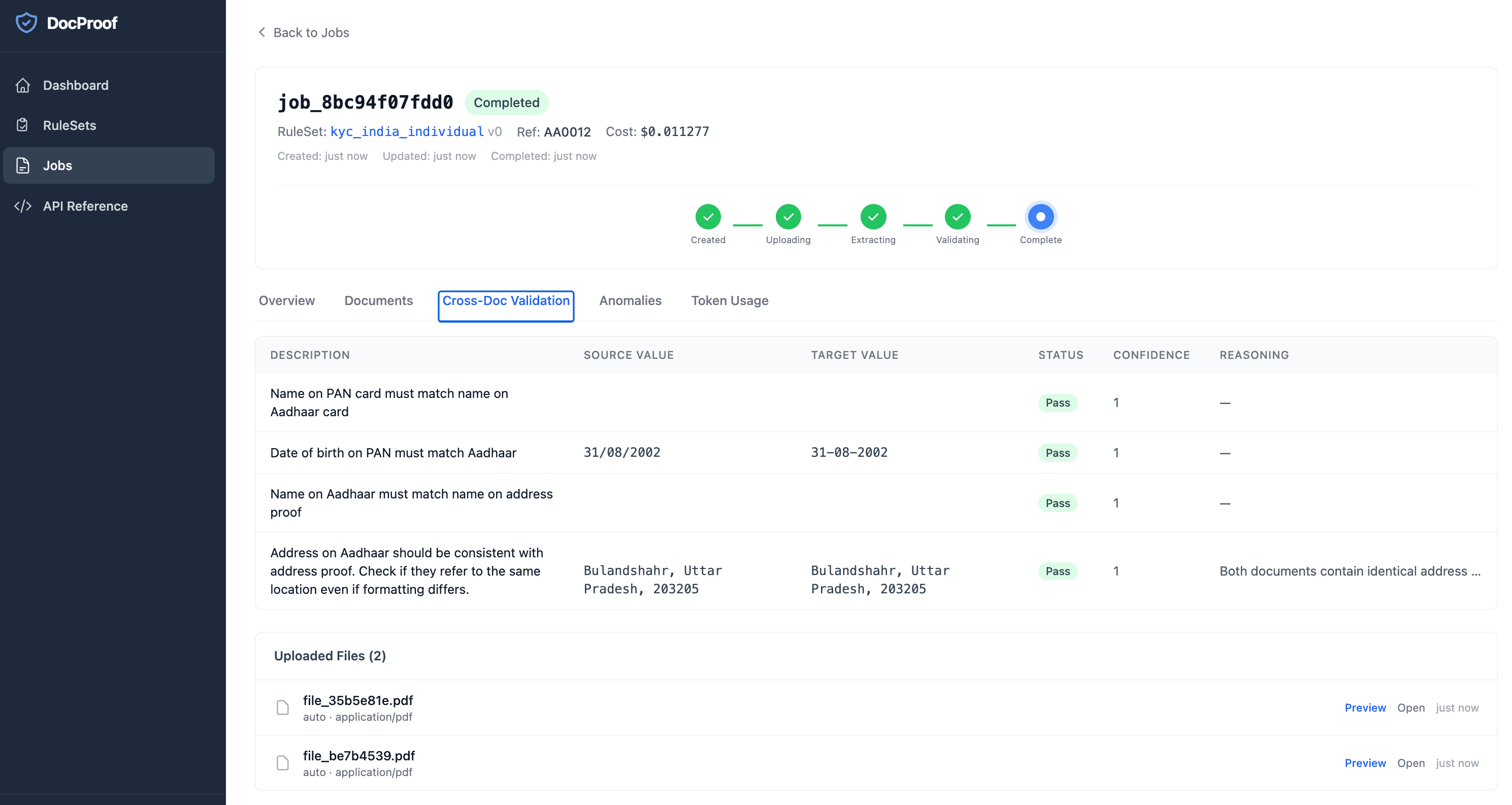
Cross-Document Validation
Verify consistency across related documents (name matching, date alignment, address correlation).
3
Anomaly Detection
Missing docs, duplicates, quality issues, suspicious patterns.
About the project
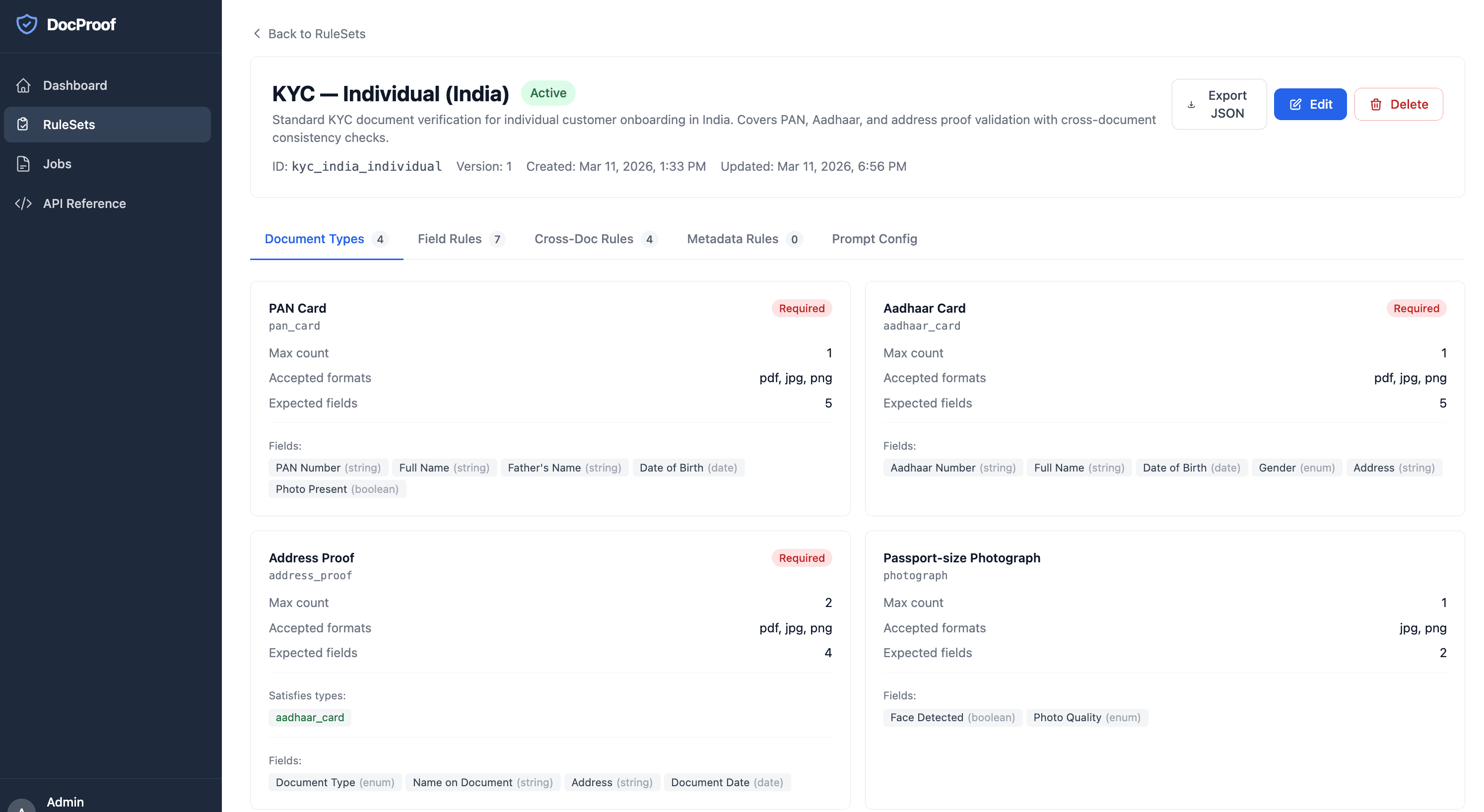
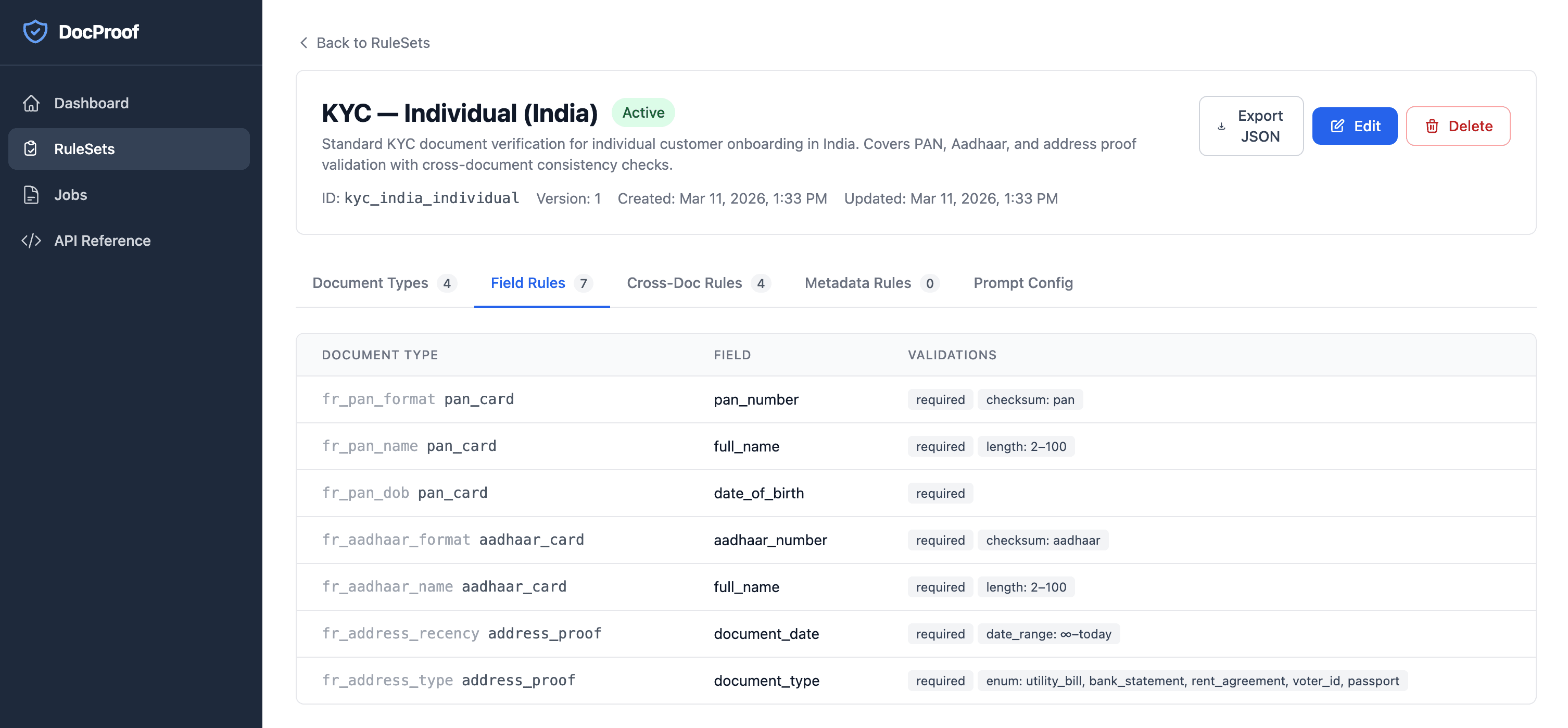
DocProof automates document collection, extraction, and validation for onboarding workflows. Define your rules. Submit your documents. Get structured results — with every check explained. From days to minutes. Replace line-by-line manual document review with AI-powered extraction and rule-based validation. Humans review anomalies, not every field.
It is built entirely on AWS serverless services. It's a deliberate architectural choice to optimize cost, security, scalability, and operational simplicity. Instead of using an autonomous AI agent, DocProof relies on a structured deterministic workflow with targeted LLM calls. This approach significantly reduces token costs, ensures consistent output, improves debuggability, and makes the processing speed fast and predictable.
This is primarily meant for Enterprises having a wide variety of use cases related to document verifications: Each requiring multiple teams to collect necessary documents, validate them through standard guidelines, and manage back-and-forth with the document provider for clarifications and corrections.
We have validated the pipeline in multiple regional Indian languages and are planning to use Sarvam AI in case some languages do not work as expected.
It is built entirely on AWS serverless services. It's a deliberate architectural choice to optimize cost, security, scalability, and operational simplicity. Instead of using an autonomous AI agent, DocProof relies on a structured deterministic workflow with targeted LLM calls. This approach significantly reduces token costs, ensures consistent output, improves debuggability, and makes the processing speed fast and predictable.
This is primarily meant for Enterprises having a wide variety of use cases related to document verifications: Each requiring multiple teams to collect necessary documents, validate them through standard guidelines, and manage back-and-forth with the document provider for clarifications and corrections.
We have validated the pipeline in multiple regional Indian languages and are planning to use Sarvam AI in case some languages do not work as expected.
Customize this for your use case? Please reach out to hello@appgambit.com
Gallery
Click to view full size
1
Click to view full size
2
Click to view full size
3

Click to view full size
4
Click to view full size
5
Click to view full size
6
Key Features
- ✓Claude-Powered Extraction: LLM-native document understanding using Haiku 4.5 via Bedrock.
- ✓Cross-Document Validation: Verify consistency across related documents (name matching, date alignment, address correlation).
- ✓Anomaly Detection: Missing docs, duplicates, quality issues, suspicious patterns.
- ✓API-First: Integrate with any CRM, ERP, or internal system.
- ✓Cost Optimized: Deterministic workflow ensures predictable cost at scale compared to unbounded AI agents.
- ✓Audit Trail: Every check documented with reasoning and confidence scores.
Tech Stack
SST v3TypeScriptReactNodeJSAWSAWS BedrockClaudeDynamoDB
Keep Exploring
Want to keep exploring?
Here's another project you can jump into next.
Next project
MyChat
Build your own Embeddable AI Chatbot Widget in minutes — no coding required!
WebOpenSource
Read next